Представление строк в памяти.
Представление строк в памяти зависит от того, насколько изменчивыми являются строки в каждой конкретной задаче, и средства такого представления варьируются от абсолютно статического до динамического. Универсальные языки программирования в основном обеспечивают работу со строками переменной длины, но максимальная длина строки должна быть указана при ее создании. Если программиста не устраивают возможности или эффективность тех средств работы со строками, которые предоставляет ему язык программирования, то он может либо определить свой тип данных "строка" и использовать для его представления средства динамической работы с памятью, либо сменить язык программирования на специально ориентированный на обработку текста (CNOBOL, REXX), в которых представление строк базируется на динамическом управлении памятью.
ВЕКТОРНОЕ ПРЕДСТАВЛЕНИЕ СТРОК.
Представление строк в виде векторов, принятое в большинстве универсальных языков программирования, позволяет работать со строками, размещенными в статической памяти. Кроме того, векторное представление позволяет легко обращаться к отдельным символам строки как к элементам вектора - по индексу.
Самым простым способом является представление строки в виде вектора постоянной длинны. При этом в памяти отводится фиксированное количество байт, в которые записываются символы строки. Если строка меньше отводимого под нее вектора, то лишние места заполняются пробелами, а если строка выходит за пределы вектора, то лишние (обычно справа строки) символы должны быть отброшены.
На рис.4.3 приведена схема, на которой показано представление двух строк: 'ABCD' и 'PQRSTUVW' в виде вектора постоянной длины на шесть символов.

Рис. 4.3. Представление строк векторами постоянной длины
ПРЕДСТАВЛЕНИЕ СТРОК ВЕКТОРОМ ПЕРЕМЕННОЙ ДЛИНЫ С ПРИЗНАКОМ КОНЦА.
Этот и все последующие за ним методы учитывают переменную длину строк. Признак конца - это особый символ, принадлежащий алфавиту (таким образом, полезный алфавит оказывается меньше на один символ), и занимает то же количество разрядов, что и все остальные символы.
Издержки памяти при этом способе составляют 1 символ на строку. Такое представление строки показано на рис.4.4. Специальный символ-маркер конца строки обозначен здесь 'eos'. В языке C, например, в качестве маркера конца строки используется символ с кодом 0.

Рис. 4.4. Представление строк переменной длины с признаком конца
ПРЕДСТАВЛЕНИЕ СТРОК ВЕКТОРОМ ПЕРЕМЕННОЙ ДЛИНЫ СО СЧЕТЧИКОМ.
Счетчик символов - это целое число, и для него отводится достаточное количество битов, чтобы их с избытком хватало для представления длины самой длинной строки,какую только можно представить в данной машине. Обычно для счетчика отводят от 8 до 16 битов. Тогда при таком представлении издержки памяти в расчете на одну строку составляют 1-2 символа. При использовании счетчика символов возможен произвольный доступ к символам в пределах строки, поскольку можно легко проверить, что обращение не выходит за пределы строки. Счетчик размещается в таком месте, где он может быть легко доступен - начале строки или в дескрипторе строки. Максимально возможная длина строки, таким образом, ограничена разрядностью счетчика. В PASCAL, например, строка представляется в виде массива символов, индексация в котором начинается с 0; однобайтный счетчик числа символов в строке является нулевым элементом этого массива. Такое представление строк показано на рис.4.5. И счетчик символов, и признак конца в предыдущем случае могут быть доступны для программиста как элементы вектора.

Рис.4.5. Представление строк переменной длины со счетчиком
В двух предыдущих вариантах обеспечивалось максимально эффективное расходование памяти (1-2 "лишних" символа на строку), но изменчивость строки обеспечивалась крайне неэффективно. Поскольку вектор - статическая структура, каждое изменение длины строки требует создания нового вектора, пересылки в него неизменяемой части строки и уничтожения старого вектора. Это сводит на нет все преимущества работы со статической памятью. Поэтому наиболее популярным способом представления строк в памяти являются вектора с управляемой длиной.
ВЕКТОР С УПРАВЛЯЕМОЙ ДЛИНОЙ.
Память под вектор с управляемой длиной отводится при создании строки и ее размер и размещение остаются неизменными все время существования строки. В дескрипторе такого вектора-строки может отсутствовать начальный индекс, так как он может быть зафиксирован раз навсегда установленными соглашениями, но появляется поле текущей длины строки. Размер строки, таким образом, может изменяться от 0 до значения максимального индекса вектора. "Лишняя" часть отводимой памяти может быть заполнена любыми кодами - она не принимается во внимание при оперировании со строкой. Поле конечного индекса может быть использовано для контроля превышения длиной строки объема отведенной памяти. Представление строк в виде вектора с управляемой длиной (при максимальной длине 10) показано на рис.4.6.
Хотя такое представление строк не обеспечивает экономии памяти, проектировщики систем программирования, как видно, считают это приемлемой платой за возможность работать с изменчивыми строками в статической памяти.
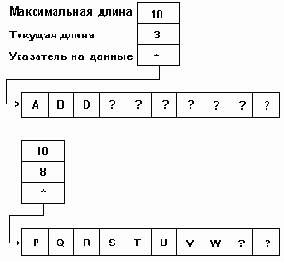
Рис.4.6. Представление строк вектором с управляемой длиной
В программном примере 4.4 приведен модуль, реализующий представление строк вектором с управляемой длиной и некоторые операции над такими строками. Для уменьшения объема в примере в секции Implementation определены не все процедуры/функции. Предоставляем читателю самостоятельно разработать прочие объявленные в секции Interface подпрограммы. Дескриптор строки описывается типом _strdescr, который в точности повторяет структуру, показанную на рис.4.6. Функция NewStr выделяет две области памяти: для дескриптора строки и для области данных строки. Адрес дескриптора строки, возвращаемый функцией NewStr - тип varstr - является той переменной, значение которой указывается пользователем модуля для идентификации конкретной строки при всех последующих операциях с нею. Область данных, указатель на которую заносится в дескрипторе строки - тип _dat_area - описана как массив символов максимального возможного объема - 64 Кбайт.
Однако, объем памяти, выделяемый под область данных функцией NewStr, как правило, меньший - он задается параметром функции. Хотя индексы в массиве символов строки теоретически могут изменяться от 1 до 65535, значение индекса в каждой конкретной строке при ее обработке ограничивается полем maxlen дескриптора данной строки. Все процедуры/функции обработки строк работают с символами строки как с элементами вектора, обращаясь к ним по индексу. Адрес вектора процедуры получают из дескриптора строки. Обратите внимание на то, что в процедуре CopyStr длина результата ограничивается максимальной длиной целевой строки.
{==== Программный пример 4.4 ====} { Представление строк вектором с управляемой длиной } Unit Vstr; Interface type _dat_area = array[1..65535] of char; type _strdescr = record { дескриптор строки } maxlen, curlen : word; { максимальная и текущая длины } strdata : ^_dat_area; { указатель на данные строки } end; type varstr = ^_strdescr; { тип - СТРОКА ПЕРЕМЕННОЙ ДЛИНЫ } Function NewStr(len : word) : varstr; Procedure DispStr(s : varstr); Function LenStr(s : varstr) : word; Procedure CopyStr(s1, s2 : varstr); Function CompStr(s1, s2 : varstr) : integer; Function PosStr(s1, s2 : varstr) : word; Procedure ConcatStr(var s1: varstr; s2 : varstr); Procedure SubStr(var s1 : varstr; n, l : word); Implementation {** Создание строки; len - максимальная длина строки; ф-ция возвращает указатель на дескриптор строки } Function NewStr(len : word) : varstr; var addr : varstr; daddr : pointer; begin New(addr); { выделение памяти для дескриптора } Getmem(daddr,len); { выделение памяти для данных } { занесение в дескриптор начальных значений } addr^.strdata:=daddr; addr^.maxlen:=len; addr^.curlen:=0; Newstr:=addr; end; { Function NewStr } Procedure DispStr(s : varstr); {** Уничтожение строки } begin FreeMem(s^.strdata,s^.maxlen); { уничтожение данных } Dispose(s); { уничтожение дескриптора } end; { Procedure DispStr } {** Определение длины строки, длина выбирается из дескриптора } Function LenStr(s : varstr) : word; begin LenStr:=s^.curlen; end; { Function LenStr } Procedure CopyStr(s1, s2 : varstr); { Присваивание строк s1:=s2} var i, len : word; begin { длина строки-результата м.б.
ограничена ее макс. длиной } if s1^.maxlen s2; -1 - если s1 < s2 } Function CompStr(s1, s2 : varstr) : integer; var i : integer; begin i:=1; { индекс текущего символа } { цикл, пока не будет достигнут конец одной из строк } while (i s2^.strdata^[i] then begin CompStr:=1; Exit; end; if s1^.strdata^[i] < s2^.strdata^[i] then begin CompStr:=-1; Exit; end; i:=i+1; { переход к следующему символу } end;
{ если выполнение дошло до этой точки, то найден конец одной из строк, и все сравненные до сих пор символы были равны; строка меньшей длины считается меньшей }
if s1^.curlens2^.curlen then CompStr:=1 else CompStr:=0; end; { Function CompStr } . . END.
СИМВОЛЬНО - СВЯЗНОЕ ПРЕДСТАВЛЕНИЕ СТРОК.
Списковое представление строк в памяти обеспечивает гибкость в выполнении разнообразных операций над строками (в частности, операций включения и исключения отдельных символов и целых цепочек) и использование системных средств управления памятью при выделении необходимого объема памяти для строки. Однако, при этом возникают дополнительные расходы памяти. Другим недостатком спискового представления строки является то, что логически соседние элементы строки не являются физически соседними в памяти. Это усложняет доступ к группам элементов строки по сравнению с доступом в векторном представлении строки.
ОДНОНАПРАВЛЕННЫЙ ЛИНЕЙНЫЙ СПИСОК.
Каждый символ строки представляется в виде элемента связного списка; элемент содержит код символа и указатель на следующий элемент, как показано на рис.4.7. Одностороннее сцепление представляет доступ только в одном направлении вдоль строки. На каждый символ строки необходим один указатель, который обычно занимает 2-4 байта.

Рис.4.7. Представление строки однонаправленным связным списком
ДВУНАПРАВЛЕННЫЙ ЛИНЕЙНЫЙ СПИСОК.
В каждый элемент списка добавляется также указатель на предыдущий элемент, как показано на рис.4.8. Двустороннее сцепление допускает двустороннее движение вдоль списка, что может значительно повысить эффективность выполнения некоторых строковых операция.
При этом на каждый символ строки необходимо два указателя , т.е. 4-8 байт.

Рис.4.8. Представление строки двунаправленным связным списком
БЛОЧНО - СВЯЗНОЕ ПРЕДСТАВЛЕНИЕ СТРОК.
Это представление позволяет в болшинстве операций избежать затрат, связанных с управлением динамической памятью, но в то же время обеспечивает достаточно эффективное использование памяти при работе со строками переменной длины.
МНОГОСИМВОЛЬНЫЕ ЗВЕНЬЯ ФИКСИРОВАННОЙ ДЛИНЫ.
Многосимвольные группы (звенья) организуются в список, так что каждый элемент списка, кроме последнего, содержит группу элементов строки и указатель следующего элемента списка. Поле указателя последнего элемента списка хранит признак конца - пустой указатель. В процессе обработки строки из любой ее позиции могут быть исключены или в любом месте вставлены элементы, в результате чего звенья могут содержать меньшее число элементов, чем было первоначально. По этой причине необходим специальный символ, который означал бы отсутствие элемента в соответствующей позиции строки. Обозначим такой символ 'emp', он не должен входить в множество символов,из которых организуется строка. Пример многосимвольных звеньев фиксированной длинны по 4 символа в звене показан на рис.4.9.
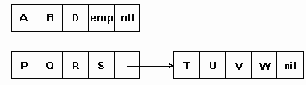
Рис. 4.9. Представление строки многосимвольными звеньями постоянной длины
Такое представление обеспечивает более эффективное использование памяти, чем символьно-связное. Операции вставки/удаления в ряде случаев могут сводиться к вставке/удалению целых блоков. Однако, при удалении одиночных символов в блоках могут накапливаться пустые символы emp, что может привести даже к худшему использованию памяти, чем в символьно-связном представлении.
МНОГОСИМВОЛЬНЫЕ ЗВЕНЬЯ ПЕРЕМЕННОЙ ДЛИНЫ.
Переменная длинна блока дает возможность избавиться от пустых символов и тем самым экономить память для строки. Однако появляется потребность в специальном символе - признаке указателя, на рис.4.10 он обозначен символом 'ptr'.
С увеличением длины групп символом, хранящихся в блоках, эффективность использования памяти повышается.
Однако негативной характеристикой рассматриваемого метода является усложнение операций по резервированию памяти для элементов списка и возврату освободившихся элементов в общий список доступной памяти.
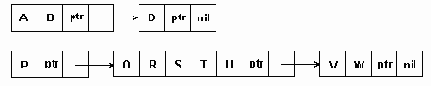
Рис.4.10. Представление строки многосимвольными звеньями переменной длины
Такой метод спискового представления строк особенно удобен в задачах редактирования текста, когда большая часть операций приходится на изменение, вставку и удаление целых слов. Поэтому в этих задачах целесообразно список организовать так, чтобы каждый его элемент содержал одно слово текста. Символы пробела между словами в памяти могут не представляются.
МНОГОСИМВОЛЬНЫЕ ЗВЕНЬЯ С УПРАВЛЯЕМОЙ ДЛИНОЙ.
Память выделяется блоками фиксированной длины. В каждом блоке помимо символов строки и указателя на следующий блок содержится номера первого и последнего символов в блоке. При обработке строки в каждом блоке обрабатываются только символы, расположенные между этими номерами. Признак пустого символа не используется: при удалении символа из строки оставшиеся в блоке символы уплотняются и корректируются граничные номера. Вставка символа может быть выполнена за счет имеющегося в блоке свободного места, а при отсутствии такового - выделением нового блока. Хотя операции вставки/удаления требуют пересылки символов, диапазон пересылок ограничивается одним блоком. При каждой операции изменения может быть проанализирована заполненность соседних блоков и два полупустых соседних блока могут быть переформированы в один блок. Для определения конца строки может использоваться как пустой указатель в последнем блоке, так и указатель на последний блок в дескрипторе строки. Последнее может быть весьма полезным при выполнении некоторых операций, например, сцепления. В дескрипторе может храниться также и длина строки: считывать ее из дескриптора удобнее, чем подсчитывать ее перебором всех блоков строки.
Пример представления строки в виде звеньев с управляемой длиной 8 показан на рис.4.11.
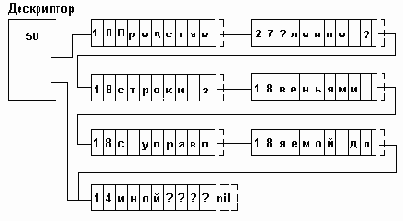
Рис.4.11. Представление строки звеньями управляемой длины
В программном примере 4. 5 приведен модуль, реализующий представление строк звеньями с управляемой длиной. Даже с первого взгляда видно, что он значительно сложнее, чем пример 4.4. Это объясняется тем, что здесь вынуждены обрабатывать как связные (списки блоков), так и векторные (массив символов в каждом блоке) структуры. Поэтому при последовательной обработке символов строки процедура должна сохранять как адрес текущего блока, так и номер текущего символа в блоке. Для этих целей во всех процедурах/функциях используются переменные cp и bi соответственно. (Процедуры и функции, обрабатывающие две строки - cp1, bi1, cp2, bi2.) Дескриптор строки - тип _strdescr - и блок - тип _block - в точности повторяют структуру, показанную на рис.4.10. Функция NewStr выделяет память только для дескриптора строки и возвращает адрес дескриптора - тип varstr - он служит идентификатором строки при последующих операциях с нею. Память для хранения данных строки выделяется только по мере необходимости. Во всех процедурах/функциях приняты такие правила работы с памятью:
- если выходной строке уже выделены блоки, используются эти уже выделенные блоки;
- если блоки, выделенные выходной строке исчерпаны, выделяются новые блоки - по мере необходимости;
- если результирующее значение выходной строки не использует все выделенные строке блоки, лишние блоки освобождаются.
Для освобождения блоков определена специальная внутренняя функция FreeBlock, освобождающая весь список блоков, голова которого задается ее параметром.
Обратите внимание на то, что ни в каких процедурах не контролируется максимальный объем строки результата - он может быть сколь угодно большим, а поле длины в дескрипторе строки имеет тип longint.
{==== Программный пример 4.5 ====} { Представление строки звеньями управляемой длины } Unit Vstr; Interface const BLKSIZE = 8; { число символов в блоке } type _bptr = ^_block; { указатель на блок } _block = record { блок } i1, i2 : byte; { номера 1-го и последнего символов } strdata : array [1..BLKSIZE] of char; { символы } next : _bptr; { указатель на следующий блок } end; type _strdescr = record { дескриптор строки } len : longint; { длина строки } first, last : _bptr; { указ.на 1-й и последний блоки } end; type varstr = ^_strdescr; { тип - СТРОКА ПЕРЕМЕННОЙ ДЛИНЫ } Function NewStr : varstr; Procedure DispStr(s : varstr); Function LenStr(s : varstr) : longint; Procedure CopyStr(s1, s2 : varstr); Function CompStr(s1, s2 : varstr) : integer; Function PosStr(s1, s2 : varstr) : word; Procedure ConcatStr(var s1: varstr; s2 : varstr); Procedure SubStr(var s : varstr; n, l : word); Implementation Function NewBlock :_bptr; {Внутр.функция-выделение нового блока} var n : _bptr; i : integer; begin New(n); { выделение памяти } n^.next:=nil; n^.i1:=0; n^.i2:=0; { начальные значения } NewBlock:=n; end; { NewBlock } {*** Внутр.функция - освобождение цепочки блока, начиная с c } Function FreeBlock(c : _bptr) : _bptr; var x : _bptr; begin { движение по цепочке с освобождением памяти } while c<>nil do begin x:=c; c:=c^.next; Dispose(x); end; FreeBlock:=nil; { всегда возвращает nil } end; { FreeBlock } Function NewStr : varstr; {** Создание строки } var addr : varstr; begin New(addr); { выделение памяти для дескриптора } { занесение в дескриптор начальных значений } addr^.len:=0; addr^.first:=nil; addr^.last:=nil; Newstr:=addr; end; { Function NewStr } Procedure DispStr(s : varstr); {** Уничтожение строки } begin s^.first:=FreeBlock(s^.first); { уничтожение блоков } Dispose(s); { уничтожение дескриптора } end; { Procedure DispStr } {** Определение длины строки, длина выбирается из дескриптора } Function LenStr(s : varstr) : longint; begin LenStr:=s^.len; end; { Function LenStr } {** Присваивание строк s1:=s2 } Procedure CopyStr(s1, s2 : varstr); var bi1, bi2 : word; { индексы символов в блоках для s1 и s2 } cp1, cp2 : _bptr; { адреса текущих блоков для s1 и s2 } pp : _bptr; { адрес предыдущего блока для s1 } begin cp1:=s1^.first; pp:=nil; cp2:=s2^.first; if s2^.len=0 then begin { если s2 пустая, освобождается вся s1 } s1^.first:=FreeBlock(s1^.first); s1^.last:=nil; end else begin while cp2<>nil do begin { перебор блоков s2 } if cp1=nil then begin { если в s1 больше нет блоков } { выделяется новый блок для s1 } cp1:=NewBlock; if s1^.first=nil then s1^.first:=cp1 else if pp<>nil then pp^.next:=cp1; end; cp1^:=cp2^; { копирование блока } { к следующему блоку } pp:=cp1; cp1:=cp1^.next; cp2:=cp2^.next; end; { while } s1^.last:=pp; { последний блок } { если в s1 остались лишние блоки - освободить их } pp^.next:=FreeBlock(pp^.next); end; { else } s1^.len:=s2^.len; end; { Procedure CopyStr } {** Сравнение строк - возвращает: 0, если s1=s2; 1 - если s1 > s2; -1 - если s1 < s2 } Function CompStr(s1, s2 : varstr) : integer; var bi1, bi2 : word; cp1, cp2 : _bptr; begin cp1:=s1^.first; cp2:=s2^.first; bi1:=cp1^.i1; bi2:=cp2^.i1; { цикл, пока не будет достигнут конец одной из строк } while (cp1<>nil) and (cp2<>nil) do begin { если соответств.символы не равны, ф-ция заканчивается } if cp1^.strdata[bi1] > cp2^.strdata[bi2] then begin CompStr:=1; Exit; end; if cp1^.strdata[bi1] < cp2^.strdata[bi2] then begin CompStr:=-1; Exit; end; bi1:=bi1+1; { к следующему символу в s1 } if bi1 > cp1^.i2 then begin cp1:=cp1^.next; bi1:=cp1^.i1; end;
bi2:=bi2+1; { к следующему символу в s2 } if bi2 > cp2^.i2 then begin cp2:=cp2^.next; bi2:=cp2^.i1; end; end; { мы дошли до конца одной из строк, строка меньшей длины считается меньшей } if s1^.len < s2^.len then CompStr:=-1 else if s1^.len > s2^.len then CompStr:=1 else CompStr:=0; end; { Function CompStr } . . END.
Чтобы не перегружать программный пример, в него не включены средства повышения эффективности работы с памятью. Такие средства включаются в операции по выбору программиста. Обратите внимание, например, что в процедуре, связанной с копированием данных (CopyStr) у нас копируются сразу целые блоки. Если в блоке исходной строки были неиспользуемые места, то они будут и в блоке результирующей строки. Посимвольное копирование позволило бы устранить избыток памяти в строке-результате. Оптимизация памяти, занимаемой данными строки может производится как слиянием соседних полупустых блоков, так и полным уплотнением данных. В дескриптор строки может быть введено поле - количество блоков в строке. Зная общее количество блоков и длину строки можно при выполнении неко- торых операций оценивать потери памяти и выполнять уплотнение, если эти потери превосходят какой-то установленный процент.
| Каталог | Индекс раздела |
| Назад | Оглавление | Вперед |
